Profiling
Quick profiling in your terminal
Note
This is only meant to be used for quick profiling or programmatically accessing the profiling results. For more detailed and GUI friendly profiling proceed to the next section.
Simply replace the use of Base.@time or Base.@timed with Reactant.Profiler.@time or Reactant.Profiler.@timed. We will automatically compile the function if it is not already a Reactant compiled function (with sync=true).
using Reactant
x = Reactant.to_rarray(randn(Float32, 100, 2))
W = Reactant.to_rarray(randn(Float32, 10, 100))
b = Reactant.to_rarray(randn(Float32, 10))
linear(x, W, b) = (W * x) .+ b
Reactant.@time linear(x, W, b)┌ Debug: Profiling directory: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:626
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1785252191.711713 4271 profiler_session.cc:171] Profiler session initializing.
I0000 00:00:1785252191.711762 4271 profiler_session.cc:186] Profiler session started.
I0000 00:00:1785252191.712124 4271 profiler_session.cc:134] Profiler session collecting data.
I0000 00:00:1785252191.712734 4271 save_profile.cc:205] Collecting XSpace to repository: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11/runnervmvrwv9.xplane.pb
I0000 00:00:1785252191.712935 4271 save_profile.cc:178] Creating directory: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
I0000 00:00:1785252191.713059 4271 save_profile.cc:184] Dumped gzipped tool data for trace.json.gz to /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11/runnervmvrwv9.trace.json.gz
I0000 00:00:1785252191.713081 4271 profiler_session.cc:217] Profiler session tear down.
┌ Debug: Starting XProf gRPC server...
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:598
┌ Debug: Initializing XProf stubs for worker service at 0.0.0.0:44051
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:397
I0000 00:00:1785252191.729476 4271 stub_factory.cc:163] Created gRPC channel for address: 0.0.0.0:44051
┌ Debug: Starting XProf gRPC server on port 44051
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:413
I0000 00:00:1785252191.729961 4271 grpc_server.cc:94] Server listening on 0.0.0.0:44051 with max_concurrent_requests 1
I0000 00:00:1785252191.739871 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: memory_profile with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
I0000 00:00:1785252191.739891 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: memory_profile
I0000 00:00:1785252191.739894 4271 memory_profile_processor.cc:47] Processing memory profile for host: runnervmvrwv9
I0000 00:00:1785252191.740215 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool memory_profile: 336.971us session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
I0000 00:00:1785252191.755351 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: op_profile with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
I0000 00:00:1785252191.755376 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: op_profile
I0000 00:00:1785252191.755380 4271 multi_xplanes_to_op_stats.cc:118] ConvertMultiXSpaceToCombinedOpStatsWithCache: Started
I0000 00:00:1785252191.755441 4271 multi_xplanes_to_op_stats.cc:134] ConvertMultiXSpaceToCombinedOpStatsWithCache: Cache miss, calling ConvertMultiXSpacesToCombinedOpStats
I0000 00:00:1785252191.755444 4271 multi_xplanes_to_op_stats.cc:45] ConvertMultiXSpacesToCombinedOpStats: Started. Number of XSpaces: 1
I0000 00:00:1785252191.755449 4271 multi_xplanes_to_op_stats.cc:55] ConvertMultiXSpacesToCombinedOpStats: Starting to process XSpace 0/1
I0000 00:00:1785252191.755614 4271 derived_timeline.cc:693] GenerateDerivedTimeLines: creating derived_timeline_trace_events XprofThreadPoolExecutor
I0000 00:00:1785252191.755624 4271 xprof_thread_pool_executor.cc:22] Creating derived_timeline_trace_events XprofThreadPoolExecutor with 4 threads.
I0000 00:00:1785252191.755890 4271 derived_timeline.cc:705] GenerateDerivedTimeLines: waiting for derived_timeline_trace_events threads to join
I0000 00:00:1785252191.756197 4271 derived_timeline.cc:709] GenerateDerivedTimeLines: derived_timeline_trace_events threads joined successfully
I0000 00:00:1785252191.756577 4271 derived_timeline.cc:758] GenerateDerivedTimeLines: creating ProcessTensorCorePlanes XprofThreadPoolExecutor
I0000 00:00:1785252191.756592 4271 xprof_thread_pool_executor.cc:22] Creating ProcessTensorCorePlanes XprofThreadPoolExecutor with 4 threads.
I0000 00:00:1785252191.756824 4271 derived_timeline.cc:769] GenerateDerivedTimeLines: waiting for ProcessTensorCorePlanes threads to join
I0000 00:00:1785252191.757154 4271 derived_timeline.cc:772] GenerateDerivedTimeLines: ProcessTensorCorePlanes threads joined successfully
I0000 00:00:1785252191.761010 4271 xplane_to_op_stats.cc:405] ConvertXSpaceToOpStats: creating op_stats_threads XprofThreadPoolExecutor
I0000 00:00:1785252191.761030 4271 xprof_thread_pool_executor.cc:22] Creating op_stats_threads XprofThreadPoolExecutor with 4 threads.
I0000 00:00:1785252191.761202 4271 xplane_to_op_stats.cc:461] ConvertXSpaceToOpStats: Scheduled 0 OpMetricsDb generation tasks.
I0000 00:00:1785252191.761437 4271 xplane_to_op_stats.cc:417] ConvertXSpaceToOpStats: Combining 0 op_metrics_dbs.
I0000 00:00:1785252191.761448 4271 xplane_to_op_stats.cc:422] ConvertXSpaceToOpStats: Finished combining op_metrics_dbs.
I0000 00:00:1785252191.761706 4271 xplane_to_op_stats.cc:687] ConvertXSpaceToOpStats: Final OpStats size: 222 bytes (0.000211716 MiB).
I0000 00:00:1785252191.761813 4271 multi_xplanes_to_op_stats.cc:67] ConvertMultiXSpacesToCombinedOpStats: Finished processing XSpace 0.
I0000 00:00:1785252191.761836 4271 multi_xplanes_to_op_stats.cc:72] ConvertMultiXSpacesToCombinedOpStats: Finished extracting all 1 OpStats. Time: 6.402833ms
I0000 00:00:1785252191.761853 4271 multi_xplanes_to_op_stats.cc:85] ConvertMultiXSpacesToCombinedOpStats: Starting ComputeStepIntersectionToMergeOpStats.
I0000 00:00:1785252191.761856 4271 multi_xplanes_to_op_stats.cc:94] ConvertMultiXSpacesToCombinedOpStats: Finished ComputeStepIntersectionToMergeOpStats in 1.623us
I0000 00:00:1785252191.761858 4271 multi_xplanes_to_op_stats.cc:99] ConvertMultiXSpacesToCombinedOpStats: Starting CombineAllOpStats.
I0000 00:00:1785252191.761863 4271 multi_xplanes_to_op_stats.cc:106] ConvertMultiXSpacesToCombinedOpStats: Finished CombineAllOpStats in 4.237us
I0000 00:00:1785252191.761865 4271 multi_xplanes_to_op_stats.cc:109] ConvertMultiXSpacesToCombinedOpStats: Overall Finished in 6.421668ms
I0000 00:00:1785252191.761868 4271 multi_xplanes_to_op_stats.cc:138] ConvertMultiXSpaceToCombinedOpStatsWithCache: Starting to write cache file.
I0000 00:00:1785252191.761963 4271 multi_xplanes_to_op_stats.cc:145] ConvertMultiXSpaceToCombinedOpStatsWithCache: Finished writing cache file.
I0000 00:00:1785252191.761967 4271 multi_xplanes_to_op_stats.cc:149] ConvertMultiXSpaceToCombinedOpStatsWithCache: Overall Finished in 6.588251ms
I0000 00:00:1785252191.762083 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool op_profile: 6.713044ms session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
┌ Debug: `op_profile` data missing keys for metrics
│ data_available_keys =
│ KeySet for a JSON.Object{String, Any} with 4 entries. Keys:
│ "byProgram"
│ "deviceType"
│ "byProgramExcludeIdle"
│ "aggDvfsTimeScaleMultiplier"
│ by_program_available_keys =
│ KeySet for a JSON.Object{String, Any} with 3 entries. Keys:
│ "name"
│ "children"
│ "numChildren"
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:816
I0000 00:00:1785252192.047570 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: overview_page with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
I0000 00:00:1785252192.047591 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: overview_page
I0000 00:00:1785252192.047595 4271 overview_page_processor.cc:84] OverviewPageProcessor::ProcessSession: Started
I0000 00:00:1785252192.047597 4271 overview_page_processor.cc:86] OverviewPageProcessor::ProcessSession: Starting ConvertMultiXSpaceToCombinedOpStatsWithCache
I0000 00:00:1785252192.047599 4271 multi_xplanes_to_op_stats.cc:118] ConvertMultiXSpaceToCombinedOpStatsWithCache: Started
I0000 00:00:1785252192.047655 4271 multi_xplanes_to_op_stats.cc:126] ConvertMultiXSpaceToCombinedOpStatsWithCache: Cache hit, reading binary proto
I0000 00:00:1785252192.047706 4271 multi_xplanes_to_op_stats.cc:131] ConvertMultiXSpaceToCombinedOpStatsWithCache: Finished reading cache file.
I0000 00:00:1785252192.047708 4271 multi_xplanes_to_op_stats.cc:149] ConvertMultiXSpaceToCombinedOpStatsWithCache: Overall Finished in 109.625us
I0000 00:00:1785252192.047713 4271 overview_page_processor.cc:90] OverviewPageProcessor::ProcessSession: Starting ConvertOpStatsToOverviewPage
I0000 00:00:1785252192.047715 4271 op_stats_to_overview_page.cc:388] ConvertOpStatsToOverviewPage: Starting ComputeRunEnvironment
I0000 00:00:1785252192.047727 4271 op_stats_to_overview_page.cc:393] ConvertOpStatsToOverviewPage: Starting ComputeAnalysisResult
I0000 00:00:1785252192.047732 4271 op_stats_to_overview_page.cc:396] ConvertOpStatsToOverviewPage: Starting ConvertOpStatsToInputPipelineAnalysis
I0000 00:00:1785252192.047908 4271 op_stats_to_overview_page.cc:401] ConvertOpStatsToOverviewPage: Starting ComputeBottleneckAnalysis
I0000 00:00:1785252192.047918 4271 op_stats_to_overview_page.cc:407] ConvertOpStatsToOverviewPage: Starting ComputeGenericRecommendation
I0000 00:00:1785252192.048023 4271 op_stats_to_overview_page.cc:412] ConvertOpStatsToOverviewPage: Starting SetCommonRecommendation
I0000 00:00:1785252192.048036 4271 op_stats_to_overview_page.cc:425] ConvertOpStatsToOverviewPage: Starting PopulateOverviewDiagnostics
I0000 00:00:1785252192.048039 4271 op_stats_to_overview_page.cc:429] ConvertOpStatsToOverviewPage: Starting setting utilizations
I0000 00:00:1785252192.048040 4271 op_stats_to_overview_page.cc:435] ConvertOpStatsToOverviewPage: Overall Finished in 325.54us
I0000 00:00:1785252192.048043 4271 overview_page_processor.cc:94] OverviewPageProcessor::ProcessSession: Not a training run, Starting to convert inference stats.
I0000 00:00:1785252192.048050 4271 xprof_thread_pool_executor.cc:22] Creating ConvertMultiXSpaceToInferenceStats XprofThreadPoolExecutor with 1 threads.
I0000 00:00:1785252192.048425 4271 overview_page_processor.cc:99] OverviewPageProcessor::ProcessSession: Starting to compute InferenceLatency
I0000 00:00:1785252192.048438 4271 overview_page_processor.cc:104] OverviewPageProcessor::ProcessSession: Starting to serialize OverviewPage toJson
I0000 00:00:1785252192.048700 4271 overview_page_processor.cc:107] OverviewPageProcessor::ProcessSession: Starting to set Output
I0000 00:00:1785252192.048710 4271 overview_page_processor.cc:109] OverviewPageProcessor::ProcessSession: Overall Finished in 1.11605ms
I0000 00:00:1785252192.048723 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool overview_page: 1.136328ms session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_ae7G6W/plugins/profile/2026_07_28_15_23_11
runtime: 0.00029013s
compile time: 4.22459771sReactant.@timed nrepeat=100 linear(x, W, b)AggregateProfilingResult(
runtime = 0.00004453s,
compile_time = 0.11950782s, )Note that the information returned depends on the backend. Specifically CUDA and TPU backends provide more detailed information regarding memory usage and allocation (something like the following will be displayed on GPUs):
AggregateProfilingResult(
runtime = 0.00003829s,
compile_time = 2.18053260s, # time spent compiling by Reactant
GPU_0_bfc = MemoryProfileSummary(
peak_bytes_usage_lifetime = 64.010 MiB, # peak memory usage over the entire program (lifetime of memory allocator)
peak_stats = MemoryAggregationStats(
stack_reserved_bytes = 0 bytes, # memory usage by stack reservation
heap_allocated_bytes = 30.750 KiB, # memory usage by heap allocation
free_memory_bytes = 23.518 GiB, # free memory available for allocation or reservation
fragmentation = 0.514931, # fragmentation of memory within [0, 1]
peak_bytes_in_use = 30.750 KiB # The peak memory usage over the entire program
)
peak_stats_time = 0.04975365s,
memory_capacity = 23.518 GiB # memory capacity of the allocator
)
flops = FlopsSummary(
Flops = 2.8369974648038653e-9, # [flops / (peak flops * program time)], capped at 1.0
UncappedFlops = 2.8369974648038653e-9,
RawFlops = 4060.0, # Total FLOPs performed
BF16Flops = 4060.0, # Total FLOPs Normalized to the bf16 (default) devices peak bandwidth
RawTime = 0.00040298422s, # Raw time in seconds
RawFlopsRate = 1.0074836180930361e7, # Raw FLOPs rate in FLOPs/seconds
BF16FlopsRate = 1.0074836180930361e7, # BF16 FLOPs rate in FLOPs/seconds
)
)Additionally for GPUs and TPUs, we can use the Reactant.@profile macro to profile the function and get information regarding each of the kernels executed.
Reactant.@profile linear(x, W, b)┌ Debug: Profiling directory: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:626
I0000 00:00:1785252192.772920 4271 profiler_session.cc:171] Profiler session initializing.
I0000 00:00:1785252192.773136 4271 profiler_session.cc:186] Profiler session started.
I0000 00:00:1785252192.773250 4271 profiler_session.cc:134] Profiler session collecting data.
I0000 00:00:1785252192.773750 4271 save_profile.cc:205] Collecting XSpace to repository: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12/runnervmvrwv9.xplane.pb
I0000 00:00:1785252192.773949 4271 save_profile.cc:178] Creating directory: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.774069 4271 save_profile.cc:184] Dumped gzipped tool data for trace.json.gz to /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12/runnervmvrwv9.trace.json.gz
I0000 00:00:1785252192.774089 4271 profiler_session.cc:217] Profiler session tear down.
I0000 00:00:1785252192.774149 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: memory_profile with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.774154 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: memory_profile
I0000 00:00:1785252192.774157 4271 memory_profile_processor.cc:47] Processing memory profile for host: runnervmvrwv9
I0000 00:00:1785252192.774301 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool memory_profile: 152.405us session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.774326 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: op_profile with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.774330 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: op_profile
I0000 00:00:1785252192.774332 4271 multi_xplanes_to_op_stats.cc:118] ConvertMultiXSpaceToCombinedOpStatsWithCache: Started
I0000 00:00:1785252192.774359 4271 multi_xplanes_to_op_stats.cc:134] ConvertMultiXSpaceToCombinedOpStatsWithCache: Cache miss, calling ConvertMultiXSpacesToCombinedOpStats
I0000 00:00:1785252192.774361 4271 multi_xplanes_to_op_stats.cc:45] ConvertMultiXSpacesToCombinedOpStats: Started. Number of XSpaces: 1
I0000 00:00:1785252192.774364 4271 multi_xplanes_to_op_stats.cc:55] ConvertMultiXSpacesToCombinedOpStats: Starting to process XSpace 0/1
I0000 00:00:1785252192.774443 4271 derived_timeline.cc:693] GenerateDerivedTimeLines: creating derived_timeline_trace_events XprofThreadPoolExecutor
I0000 00:00:1785252192.774451 4271 xprof_thread_pool_executor.cc:22] Creating derived_timeline_trace_events XprofThreadPoolExecutor with 4 threads.
I0000 00:00:1785252192.774646 4271 derived_timeline.cc:705] GenerateDerivedTimeLines: waiting for derived_timeline_trace_events threads to join
I0000 00:00:1785252192.774936 4271 derived_timeline.cc:709] GenerateDerivedTimeLines: derived_timeline_trace_events threads joined successfully
I0000 00:00:1785252192.775354 4271 derived_timeline.cc:758] GenerateDerivedTimeLines: creating ProcessTensorCorePlanes XprofThreadPoolExecutor
I0000 00:00:1785252192.775378 4271 xprof_thread_pool_executor.cc:22] Creating ProcessTensorCorePlanes XprofThreadPoolExecutor with 4 threads.
I0000 00:00:1785252192.775516 4271 derived_timeline.cc:769] GenerateDerivedTimeLines: waiting for ProcessTensorCorePlanes threads to join
I0000 00:00:1785252192.775762 4271 derived_timeline.cc:772] GenerateDerivedTimeLines: ProcessTensorCorePlanes threads joined successfully
I0000 00:00:1785252192.776263 4271 xplane_to_op_stats.cc:405] ConvertXSpaceToOpStats: creating op_stats_threads XprofThreadPoolExecutor
I0000 00:00:1785252192.776288 4271 xprof_thread_pool_executor.cc:22] Creating op_stats_threads XprofThreadPoolExecutor with 4 threads.
I0000 00:00:1785252192.776425 4271 xplane_to_op_stats.cc:461] ConvertXSpaceToOpStats: Scheduled 0 OpMetricsDb generation tasks.
I0000 00:00:1785252192.776675 4271 xplane_to_op_stats.cc:417] ConvertXSpaceToOpStats: Combining 0 op_metrics_dbs.
I0000 00:00:1785252192.776684 4271 xplane_to_op_stats.cc:422] ConvertXSpaceToOpStats: Finished combining op_metrics_dbs.
I0000 00:00:1785252192.776883 4271 xplane_to_op_stats.cc:687] ConvertXSpaceToOpStats: Final OpStats size: 265 bytes (0.000252724 MiB).
I0000 00:00:1785252192.776967 4271 multi_xplanes_to_op_stats.cc:67] ConvertMultiXSpacesToCombinedOpStats: Finished processing XSpace 0.
I0000 00:00:1785252192.777016 4271 multi_xplanes_to_op_stats.cc:72] ConvertMultiXSpacesToCombinedOpStats: Finished extracting all 1 OpStats. Time: 2.65904ms
I0000 00:00:1785252192.777023 4271 multi_xplanes_to_op_stats.cc:85] ConvertMultiXSpacesToCombinedOpStats: Starting ComputeStepIntersectionToMergeOpStats.
I0000 00:00:1785252192.777026 4271 multi_xplanes_to_op_stats.cc:94] ConvertMultiXSpacesToCombinedOpStats: Finished ComputeStepIntersectionToMergeOpStats in 1.672us
I0000 00:00:1785252192.777028 4271 multi_xplanes_to_op_stats.cc:99] ConvertMultiXSpacesToCombinedOpStats: Starting CombineAllOpStats.
I0000 00:00:1785252192.777033 4271 multi_xplanes_to_op_stats.cc:106] ConvertMultiXSpacesToCombinedOpStats: Finished CombineAllOpStats in 3.646us
I0000 00:00:1785252192.777035 4271 multi_xplanes_to_op_stats.cc:109] ConvertMultiXSpacesToCombinedOpStats: Overall Finished in 2.673798ms
I0000 00:00:1785252192.777038 4271 multi_xplanes_to_op_stats.cc:138] ConvertMultiXSpaceToCombinedOpStatsWithCache: Starting to write cache file.
I0000 00:00:1785252192.777088 4271 multi_xplanes_to_op_stats.cc:145] ConvertMultiXSpaceToCombinedOpStatsWithCache: Finished writing cache file.
I0000 00:00:1785252192.777091 4271 multi_xplanes_to_op_stats.cc:149] ConvertMultiXSpaceToCombinedOpStatsWithCache: Overall Finished in 2.759277ms
I0000 00:00:1785252192.777113 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool op_profile: 2.785747ms session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
┌ Debug: `op_profile` data missing keys for metrics
│ data_available_keys =
│ KeySet for a JSON.Object{String, Any} with 4 entries. Keys:
│ "byProgram"
│ "deviceType"
│ "byProgramExcludeIdle"
│ "aggDvfsTimeScaleMultiplier"
│ by_program_available_keys =
│ KeySet for a JSON.Object{String, Any} with 3 entries. Keys:
│ "name"
│ "children"
│ "numChildren"
└ @ Reactant.Profiler ~/work/Reactant.jl/Reactant.jl/src/Profiler.jl:816
I0000 00:00:1785252192.777443 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: overview_page with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.777450 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: overview_page
I0000 00:00:1785252192.777452 4271 overview_page_processor.cc:84] OverviewPageProcessor::ProcessSession: Started
I0000 00:00:1785252192.777454 4271 overview_page_processor.cc:86] OverviewPageProcessor::ProcessSession: Starting ConvertMultiXSpaceToCombinedOpStatsWithCache
I0000 00:00:1785252192.777456 4271 multi_xplanes_to_op_stats.cc:118] ConvertMultiXSpaceToCombinedOpStatsWithCache: Started
I0000 00:00:1785252192.777488 4271 multi_xplanes_to_op_stats.cc:126] ConvertMultiXSpaceToCombinedOpStatsWithCache: Cache hit, reading binary proto
I0000 00:00:1785252192.777521 4271 multi_xplanes_to_op_stats.cc:131] ConvertMultiXSpaceToCombinedOpStatsWithCache: Finished reading cache file.
I0000 00:00:1785252192.777524 4271 multi_xplanes_to_op_stats.cc:149] ConvertMultiXSpaceToCombinedOpStatsWithCache: Overall Finished in 68.579us
I0000 00:00:1785252192.777526 4271 overview_page_processor.cc:90] OverviewPageProcessor::ProcessSession: Starting ConvertOpStatsToOverviewPage
I0000 00:00:1785252192.777528 4271 op_stats_to_overview_page.cc:388] ConvertOpStatsToOverviewPage: Starting ComputeRunEnvironment
I0000 00:00:1785252192.777532 4271 op_stats_to_overview_page.cc:393] ConvertOpStatsToOverviewPage: Starting ComputeAnalysisResult
I0000 00:00:1785252192.777536 4271 op_stats_to_overview_page.cc:396] ConvertOpStatsToOverviewPage: Starting ConvertOpStatsToInputPipelineAnalysis
I0000 00:00:1785252192.777564 4271 op_stats_to_overview_page.cc:401] ConvertOpStatsToOverviewPage: Starting ComputeBottleneckAnalysis
I0000 00:00:1785252192.777569 4271 op_stats_to_overview_page.cc:407] ConvertOpStatsToOverviewPage: Starting ComputeGenericRecommendation
I0000 00:00:1785252192.777574 4271 op_stats_to_overview_page.cc:412] ConvertOpStatsToOverviewPage: Starting SetCommonRecommendation
I0000 00:00:1785252192.777579 4271 op_stats_to_overview_page.cc:425] ConvertOpStatsToOverviewPage: Starting PopulateOverviewDiagnostics
I0000 00:00:1785252192.777581 4271 op_stats_to_overview_page.cc:429] ConvertOpStatsToOverviewPage: Starting setting utilizations
I0000 00:00:1785252192.777583 4271 op_stats_to_overview_page.cc:435] ConvertOpStatsToOverviewPage: Overall Finished in 54.873us
I0000 00:00:1785252192.777585 4271 overview_page_processor.cc:94] OverviewPageProcessor::ProcessSession: Not a training run, Starting to convert inference stats.
I0000 00:00:1785252192.777589 4271 xprof_thread_pool_executor.cc:22] Creating ConvertMultiXSpaceToInferenceStats XprofThreadPoolExecutor with 1 threads.
I0000 00:00:1785252192.777882 4271 overview_page_processor.cc:99] OverviewPageProcessor::ProcessSession: Starting to compute InferenceLatency
I0000 00:00:1785252192.777893 4271 overview_page_processor.cc:104] OverviewPageProcessor::ProcessSession: Starting to serialize OverviewPage toJson
I0000 00:00:1785252192.778091 4271 overview_page_processor.cc:107] OverviewPageProcessor::ProcessSession: Starting to set Output
I0000 00:00:1785252192.778100 4271 overview_page_processor.cc:109] OverviewPageProcessor::ProcessSession: Overall Finished in 648.575us
I0000 00:00:1785252192.778111 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool overview_page: 664.395us session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.871172 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: kernel_stats with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252192.871199 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: kernel_stats
I0000 00:00:1785252192.871203 4271 multi_xplanes_to_op_stats.cc:118] ConvertMultiXSpaceToCombinedOpStatsWithCache: Started
I0000 00:00:1785252192.871261 4271 multi_xplanes_to_op_stats.cc:126] ConvertMultiXSpaceToCombinedOpStatsWithCache: Cache hit, reading binary proto
I0000 00:00:1785252192.871316 4271 multi_xplanes_to_op_stats.cc:131] ConvertMultiXSpaceToCombinedOpStatsWithCache: Finished reading cache file.
I0000 00:00:1785252192.871319 4271 multi_xplanes_to_op_stats.cc:149] ConvertMultiXSpaceToCombinedOpStatsWithCache: Overall Finished in 116.007us
I0000 00:00:1785252192.871384 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool kernel_stats: 189.756us session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252193.003728 4271 xplane_to_tools_data_with_profile_processor.cc:142] serving tool: framework_op_stats with options: {} using ProfileProcessor session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
I0000 00:00:1785252193.003755 4271 xplane_to_tools_data_with_profile_processor.cc:165] Using local processing for tool: framework_op_stats
I0000 00:00:1785252193.003759 4271 multi_xplanes_to_op_stats.cc:118] ConvertMultiXSpaceToCombinedOpStatsWithCache: Started
I0000 00:00:1785252193.003841 4271 multi_xplanes_to_op_stats.cc:126] ConvertMultiXSpaceToCombinedOpStatsWithCache: Cache hit, reading binary proto
I0000 00:00:1785252193.003891 4271 multi_xplanes_to_op_stats.cc:131] ConvertMultiXSpaceToCombinedOpStatsWithCache: Finished reading cache file.
I0000 00:00:1785252193.003894 4271 multi_xplanes_to_op_stats.cc:149] ConvertMultiXSpaceToCombinedOpStatsWithCache: Overall Finished in 135.183us
I0000 00:00:1785252193.004042 4271 xplane_to_tools_data_with_profile_processor.cc:170] Total time for tool framework_op_stats: 290.965us session_id: /home/runner/.julia/scratchspaces/3c362404-f566-11ee-1572-e11a4b42c853/reactant_profiling/jl_dKHqWI/plugins/profile/2026_07_28_15_23_12
╔================================================================================╗
║ SUMMARY ║
╚================================================================================╝
AggregateProfilingResult(
runtime = 0.00008869s,
compile_time = 0.10939579s, # time spent compiling by Reactant
)On GPUs this would look something like the following:
╔================================================================================╗
║ KERNEL STATISTICS ║
╚================================================================================╝
┌───────────────────┬─────────────┬────────────────┬──────────────┬──────────────┬──────────────┬──────────────┬───────────┬──────────┬────────────┬─────────────┐
│ Kernel Name │ Occurrences │ Total Duration │ Avg Duration │ Min Duration │ Max Duration │ Static Shmem │ Block Dim │ Grid Dim │ TensorCore │ Occupancy % │
├───────────────────┼─────────────┼────────────────┼──────────────┼──────────────┼──────────────┼──────────────┼───────────┼──────────┼────────────┼─────────────┤
│ gemm_fusion_dot_1 │ 1 │ 0.00000250s │ 0.00000250s │ 0.00000250s │ 0.00000250s │ 2.000 KiB │ 64,1,1 │ 1,1,1 │ ✗ │ 100.0% │
│ loop_add_fusion │ 1 │ 0.00000131s │ 0.00000131s │ 0.00000131s │ 0.00000131s │ 0 bytes │ 20,1,1 │ 1,1,1 │ ✗ │ 31.2% │
└───────────────────┴─────────────┴────────────────┴──────────────┴──────────────┴──────────────┴──────────────┴───────────┴──────────┴────────────┴─────────────┘
╔================================================================================╗
║ FRAMEWORK OP STATISTICS ║
╚================================================================================╝
┌───────────────────┬─────────┬─────────────┬─────────────┬─────────────────┬───────────────┬──────────┬───────────┬──────────────┬──────────┐
│ Operation │ Type │ Host/Device │ Occurrences │ Total Self-Time │ Avg Self-Time │ Device % │ Memory BW │ FLOP Rate │ Bound By │
├───────────────────┼─────────┼─────────────┼─────────────┼─────────────────┼───────────────┼──────────┼───────────┼──────────────┼──────────┤
│ gemm_fusion_dot.1 │ Unknown │ Device │ 1 │ 0.00000250s │ 0.00000250s │ 65.55% │ 1.82 GB/s │ 1.6 GFLOP/s │ HBM │
│ +/add │ add │ Device │ 1 │ 0.00000131s │ 0.00000131s │ 34.45% │ 0.14 GB/s │ 0.05 GFLOP/s │ HBM │
└───────────────────┴─────────┴─────────────┴─────────────┴─────────────────┴───────────────┴──────────┴───────────┴──────────────┴──────────┘
╔================================================================================╗
║ SUMMARY ║
╚================================================================================╝
AggregateProfilingResult(
runtime = 0.00005622s,
compile_time = 2.32802137s, # time spent compiling by Reactant
GPU_0_bfc = MemoryProfileSummary(
peak_bytes_usage_lifetime = 64.010 MiB, # peak memory usage over the entire program (lifetime of memory allocator)
peak_stats = MemoryAggregationStats(
stack_reserved_bytes = 0 bytes, # memory usage by stack reservation
heap_allocated_bytes = 81.750 KiB, # memory usage by heap allocation
free_memory_bytes = 23.518 GiB, # free memory available for allocation or reservation
fragmentation = 0.514564, # fragmentation of memory within [0, 1]
peak_bytes_in_use = 81.750 KiB # The peak memory usage over the entire program
)
peak_stats_time = 0.00608052s,
memory_capacity = 23.518 GiB # memory capacity of the allocator
)
flops = FlopsSummary(
Flops = 2.033375207640664e-8, # [flops / (peak flops * program time)], capped at 1.0
UncappedFlops = 2.033375207640664e-8,
RawFlops = 4060.0, # Total FLOPs performed
BF16Flops = 4060.0, # Total FLOPs Normalized to the bf16 (default) devices peak bandwidth
RawTime = 0.00005622s, # Raw time in seconds
RawFlopsRate = 7.220987105380169e7, # Raw FLOPs rate in FLOPs/seconds
BF16FlopsRate = 7.220987105380169e7, # BF16 FLOPs rate in FLOPs/seconds
)
)Capturing traces
When running Reactant, it is possible to capture traces using the XLA profiler. These traces can provide information about where the XLA specific parts of program spend time during compilation or execution. Note that tracing and compilation happen on the CPU even though the final execution is aimed to run on another device such as GPU or TPU. Therefore, including tracing and compilation in a trace will create annotations on the CPU.
Let's setup a simple function which we can then profile
using Reactant
x = Reactant.to_rarray(randn(Float32, 100, 2))
W = Reactant.to_rarray(randn(Float32, 10, 100))
b = Reactant.to_rarray(randn(Float32, 10))
linear(x, W, b) = (W * x) .+ blinear (generic function with 1 method)The profiler can be accessed using the Reactant.with_profiler function.
Reactant.with_profiler("./") do
mylinear = Reactant.@compile linear(x, W, b)
mylinear(x, W, b)
end10×2 ConcretePJRTArray{Float32,2}:
4.91914 -1.40594
-4.77077 -10.1923
-2.45706 0.856256
4.07915 -17.9209
-1.50257 5.12977
4.06189 -7.42305
22.1266 -11.1266
-3.73778 8.55052
-2.22085 -9.85001
6.00938 10.2365Running this function should create a folder called plugins in the folder provided to Reactant.with_profiler which will contain the trace files. The traces can then be visualized in different ways.
Note
For more insights about the current state of Reactant, it is possible to fetch device information about allocations using the Reactant.XLA.allocatorstats function.
Perfetto UI
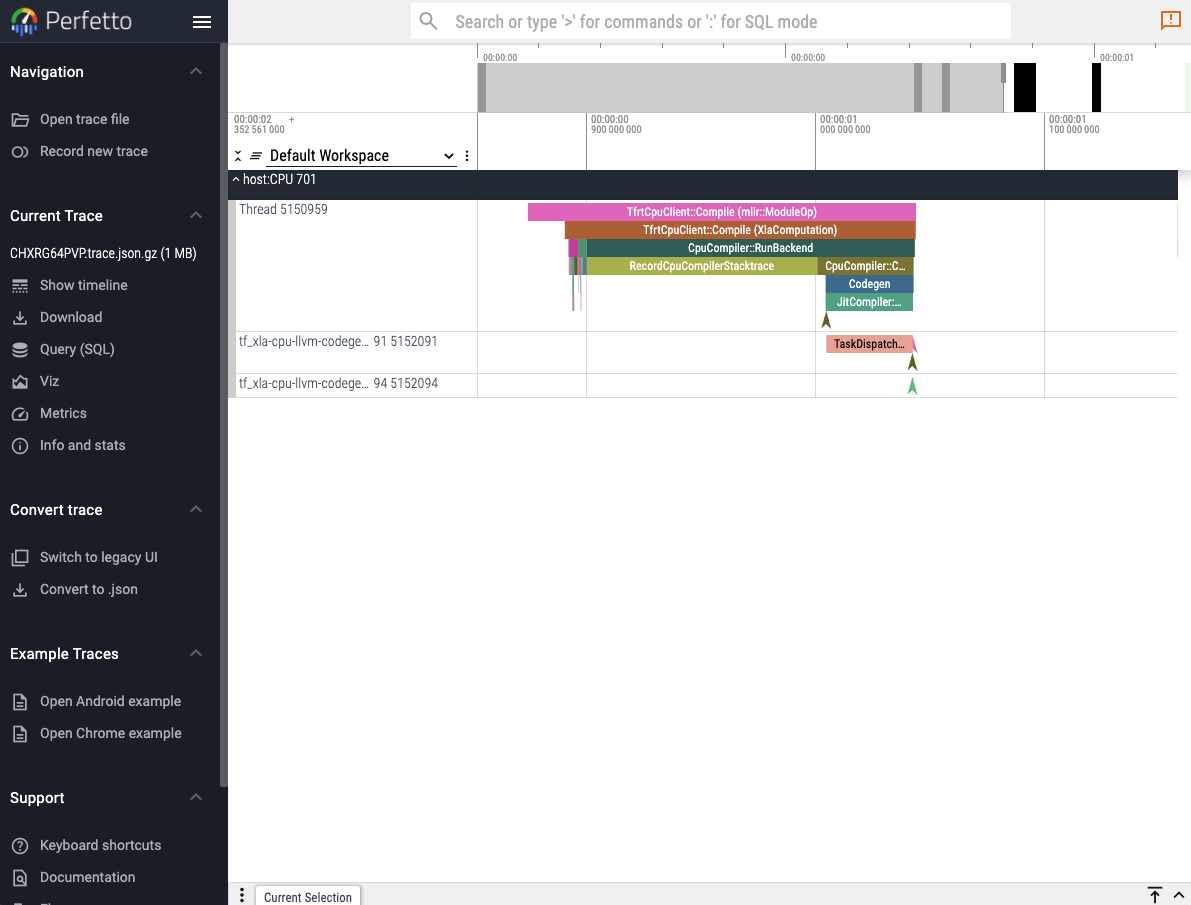
The first and easiest way to visualize a captured trace is to use the online perfetto.dev tool. Reactant.with_profiler has a keyword parameter called create_perfetto_link which will create a usable perfetto URL for the generated trace. The function will block execution until the URL has been clicked and the trace is visualized. The URL only works once.
Reactant.with_profiler("./"; create_perfetto_link=true) do
mylinear = Reactant.@compile linear(x, W, b)
mylinear(x, W, b)
endNote
It is recommended to use the Chrome browser to open the perfetto URL.
XProf
XProf is a complete web UI to analyze the log files captured by Reactant. It can be installed in the following manner:
pip install xprof # or xprof-nightlyLaunching xprof is then as simple as:
xprof --logdir=./which will then make the xprof interface available on port :8791 by default.
Tensorboard
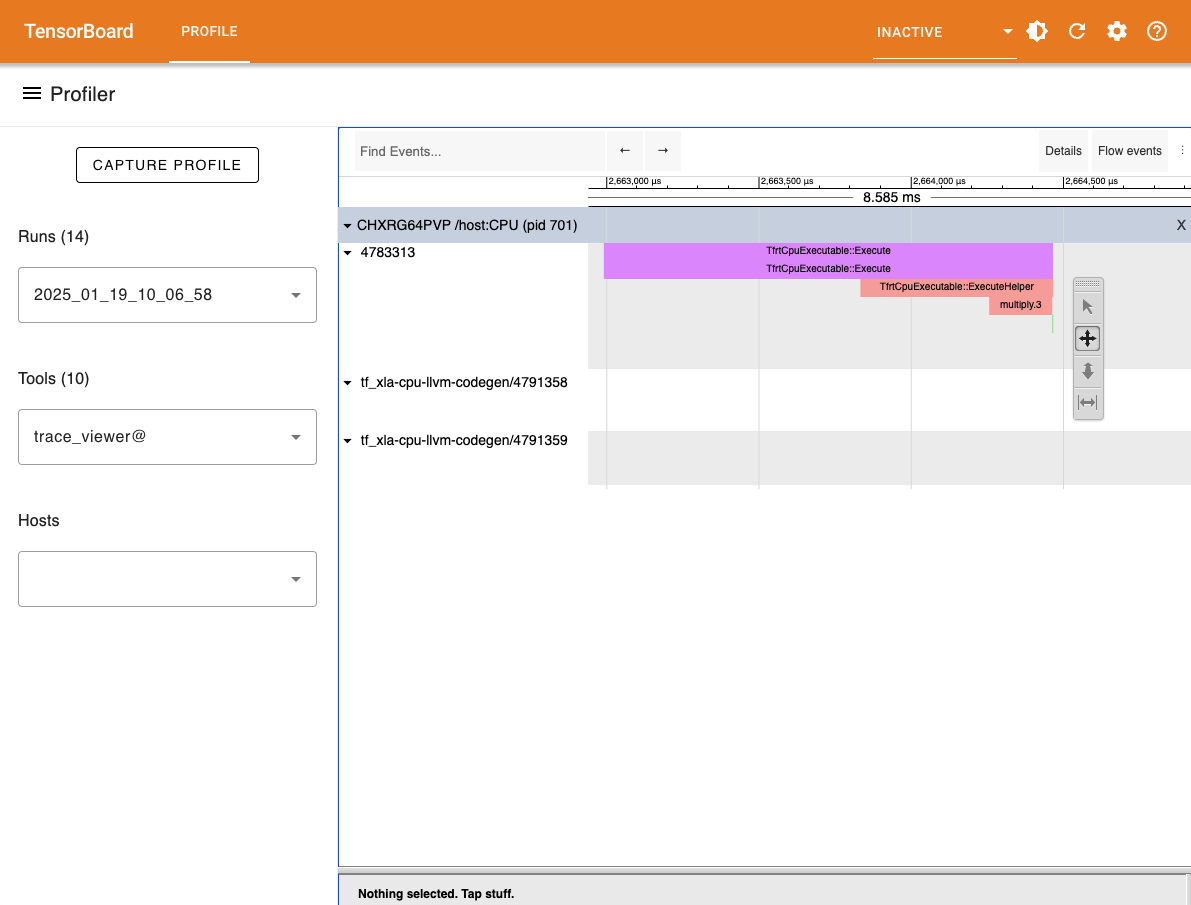
Another option to visualize the generated trace files is to use the tensorboard profiler plugin. The tensorboard viewer can offer more details than the timeline view such as visualization for compute graphs.
First install tensorboard and its profiler plugin:
pip install tensorboard tensorboard-plugin-profileAnd then run the following in the folder where the plugins folder was generated:
tensorboard --logdir ./Adding Custom Annotations
By default, the traces contain only information captured from within XLA. The Reactant.Profiler.annotate function can be used to annotate traces for Julia code evaluated during tracing.
Reactant.Profiler.annotate("my_annotation") do
# Do things...
endThe added annotations will be captured in the traces and can be seen in the different viewers along with the default XLA annotations. When the profiler is not activated, then the custom annotations have no effect and can therefore always be activated.